Big data with Modern R & Spark in Public Statistics | |
|
"SEMINAR: Análisis de Big data con Tidyverse y Spark: uso en estadística pública"
Monday September 14, 2020. 16h-17:30h + questions
Within the context of the postgraduate course on
"Data Science. Applications to Biology and Medicine with Python and R"
at University of Barcelona. 2020.
| |
Outline | |
| |
(1) About me | |
|
Xavier de Pedro Puente, Ph.D. xavier.depedro (a) seeds4c.org
Disclaimer
The views expressed in this presentation are those of the author and do not necessarily represent the views and policies of the Barcelona City Council. Any mention of trade names, products or services does not imply an endorsement by the Barcelona City Council unless explicitly stated as such.
| |
(2) Barcelona City Council Case | |
| |
Barcelona City Council: Public money - public code | |
| |
Barcelona City Council: CityOS | |
|
City Council's infrastructure based on open-source Big Data technology City OS: internal data management, known as "Data Lake"
| |
Barcelona City Council: CityOS Technologies | |
|
CityOS technologies: GNU/Linux, CentOS, Cloudera, Activiti, Talend, Protégé, R, Zabbix, Nagios, Ganglia
| |
Barcelona City Council: CityOS - Cloudera Manager | |
|
Cloudera with Hadoop File System, Hue, HBase, Hive, Impala, Oozie, Spark, Yarn, Kafka, ...
| |
(3) From Base R to "Modern R": Tidyverse | |
| |

Modern R (Tidyverse) | |||
|
Workflow, Packages, People/Community
| |||
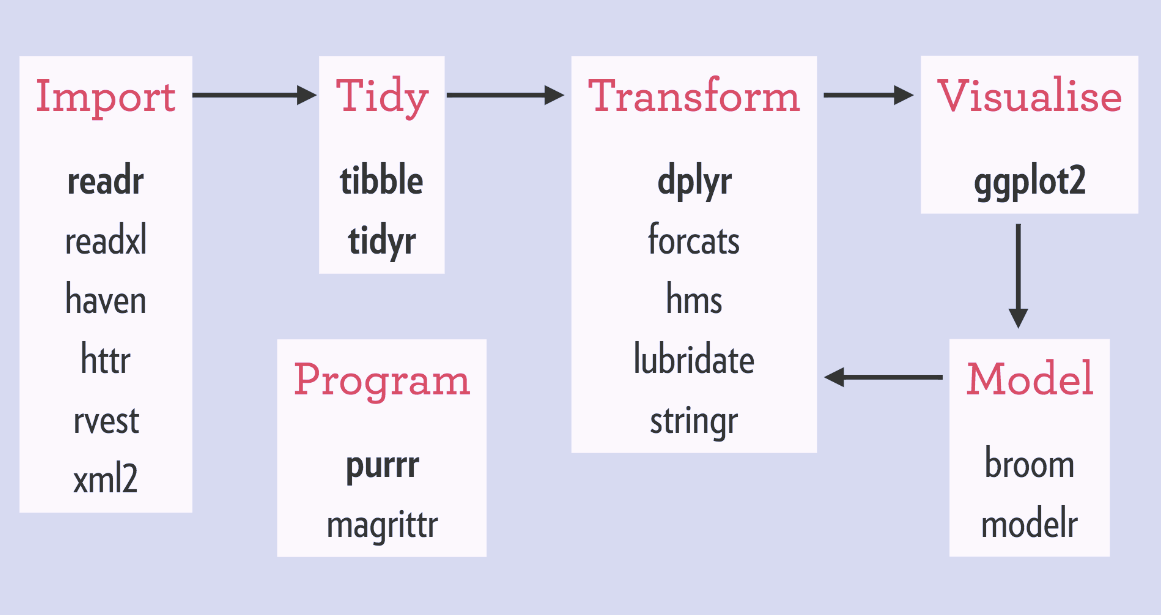


Modern R (Tidyverse) principles | |
| |
(4) Modern R & Big Data | |
|
Data > RAM = Problem
From an RStudio seminar by Garrett Grolemund | |
3 classes of Big Data Problems | |
|
From an RStudio seminar by Garrett Grolemund
| |
R interacts with other technologies | |
|
From an RStudio seminar by Garrett Grolemund | |
R General Strategy (i): Class 1 & 2 | |
|
From an RStudio seminar by Garrett Grolemund | |
R General Strategy (ii): Class 1 & 2 | |
|
From an RStudio seminar by Garrett Grolemund | |
R General Strategy (iii): Class 3 | |
|
From an RStudio seminar by Garrett Grolemund | |
Class 3 - dbplyr | |
|
R - tidyverse - dplyr + dbplyr
From an RStudio seminar by Garrett Grolemund | |
R General Strategy (iv): Recap | |
|
From an RStudio seminar by Garrett Grolemund | |
(5) Spark (Apache) & sparklyr (Rstudio) | |
|
| |
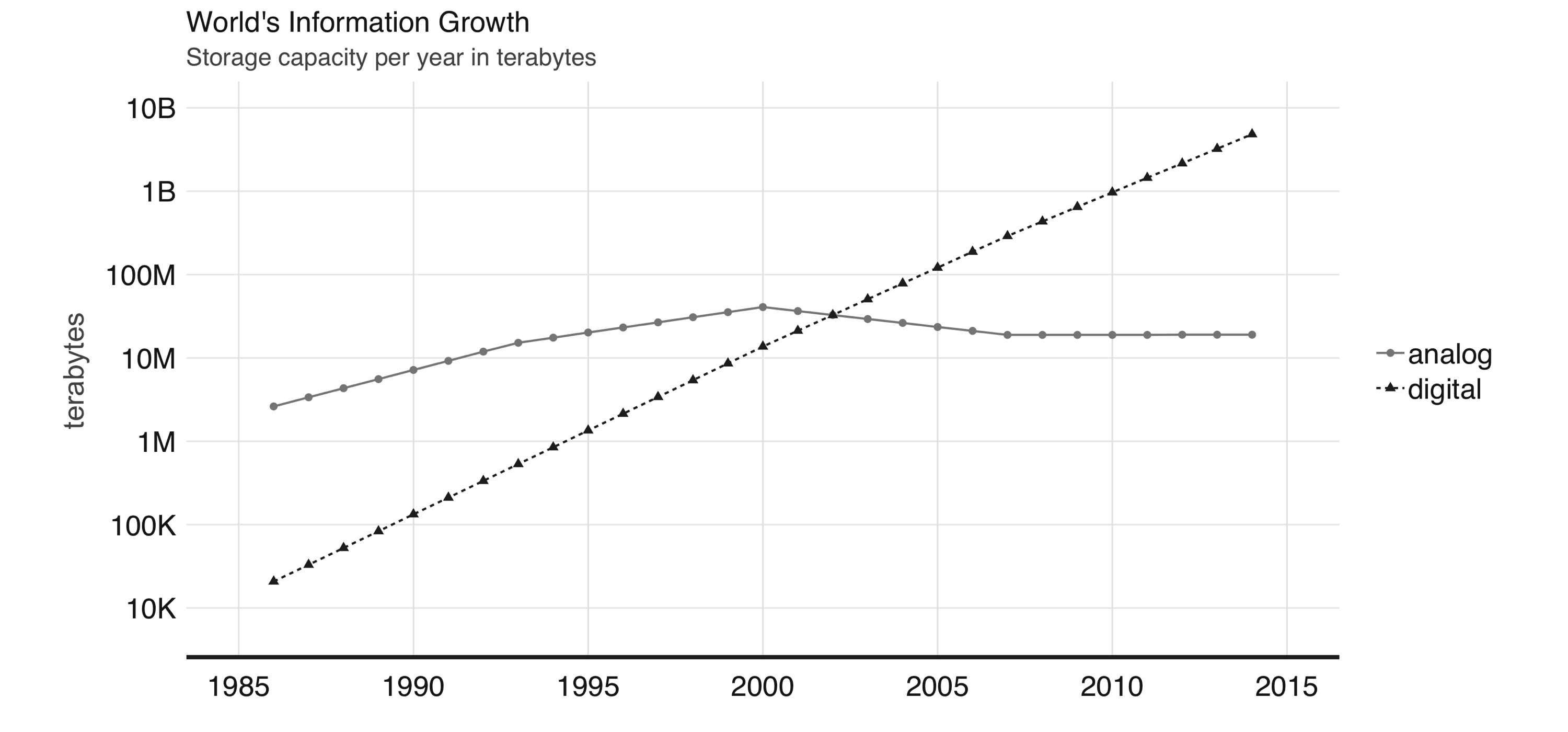
Digital information vs analog information | World Bank - 2003 | |
| |
Google File System | Google - 2003 | |
| |
MapReduce | Google - 2004 | |
| |
Hadoop Distributed File System (HDFS) | Yahoo - 2006 | |
From "The R In Spark" (book) | Image from De Apache Software Foundation, with Apache License 2.0 | |
Hive | Facebook - 2008 | |
From "The R In Spark" (book) | Image from Davod with Apache License 2.0 | |
Spark (closed sourced) | UCBerkely - 2009 | |
| |
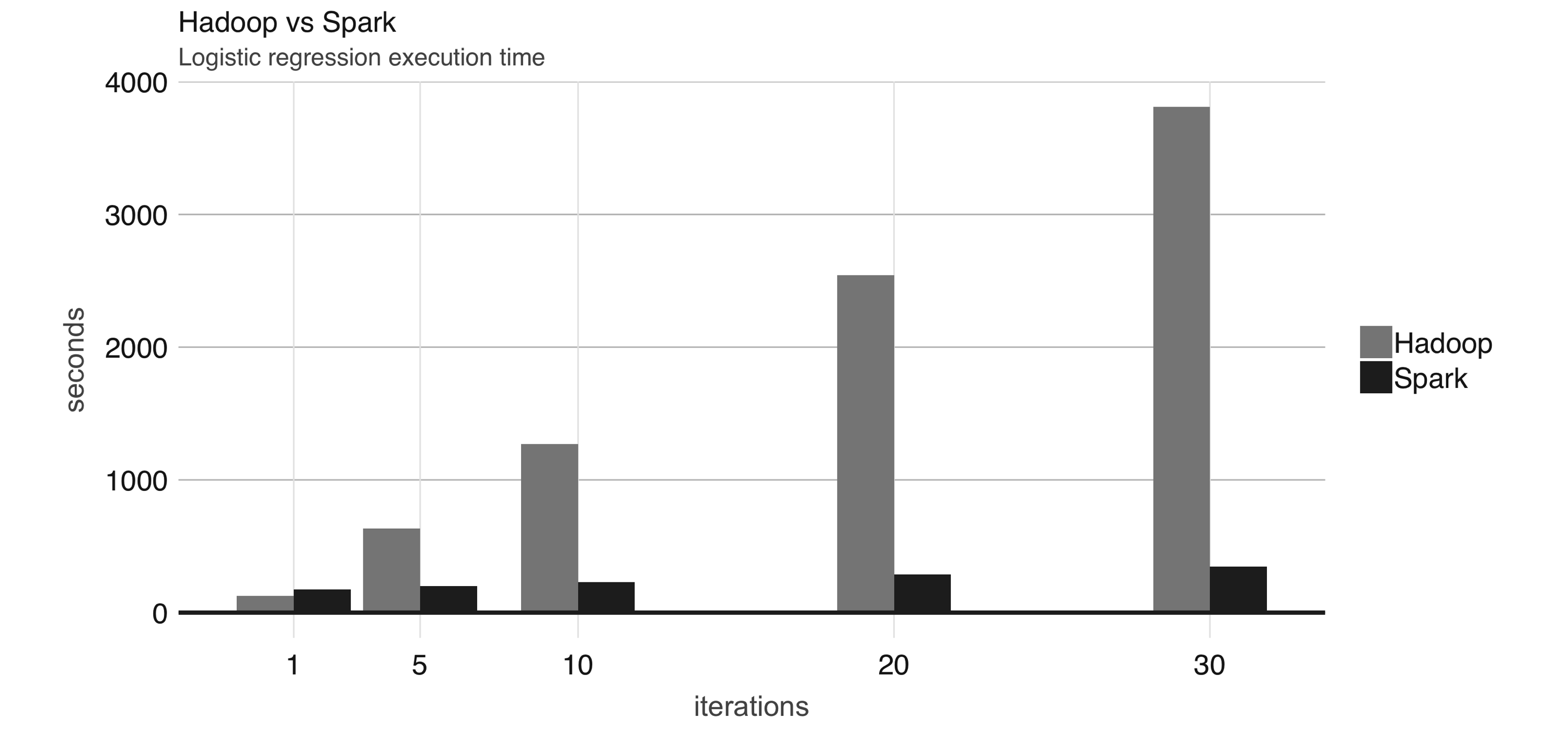
Spark: In-memory and on-disk | |
| |
Spark: faster and easier | |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
Spark (open sourced) - 2010 | Apache Foundation - 2013 | |||
| |||
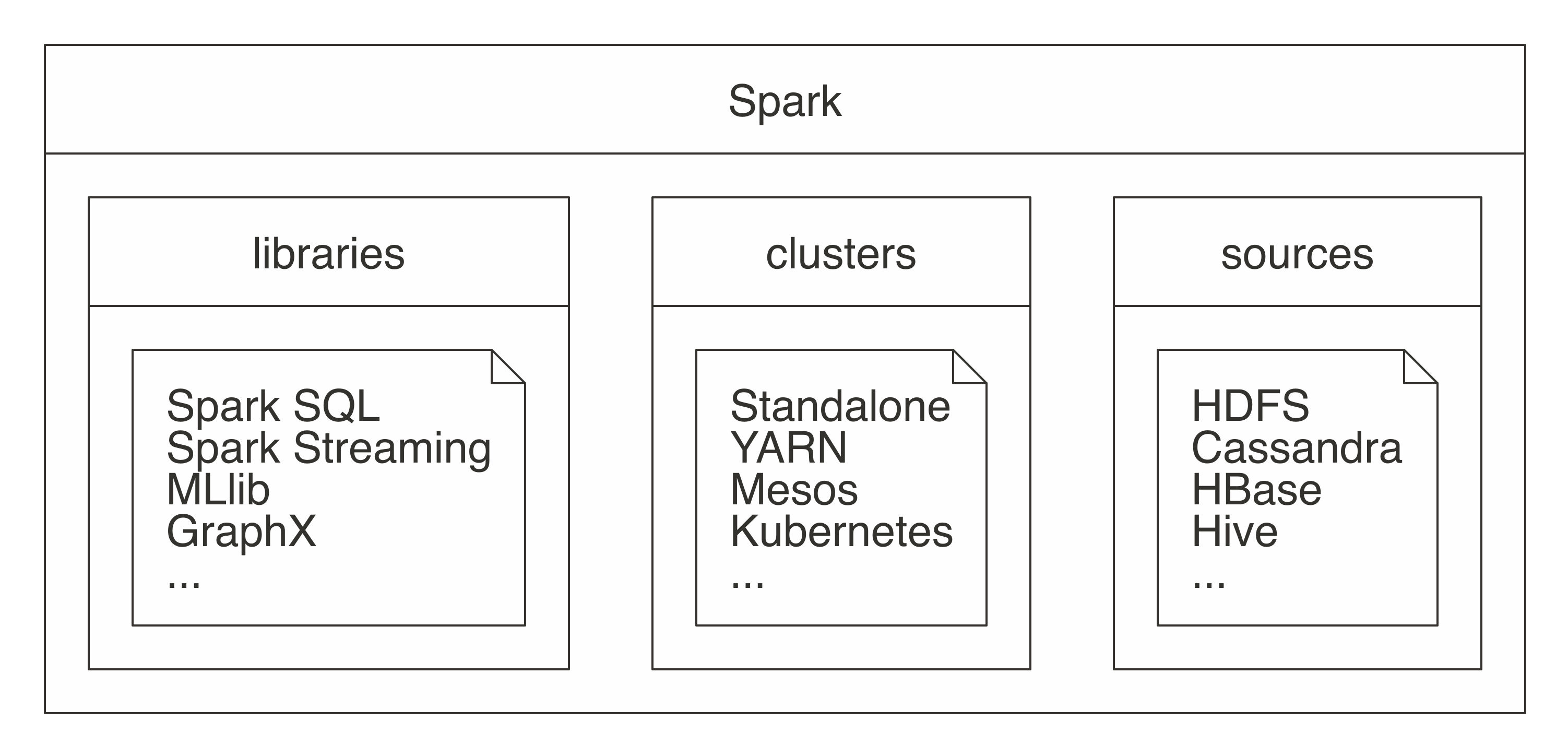
SparkR (Base R) vs. sparklyr (Modern R) | |||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||
Sparklyr | RStudio | |
Image from here | |
Summary: Big Data with Modern R & Spark | |
|
Big Data with Modern R & Spark in context
Image from here | |
Speeding up Spark via R with Apache Arrow | |||
|
Apache Arrow is a cross-language development platform for in-memory data, you can read more about this in the Arrow and beyond blog post. In sparklyr 1.0, we are embracing Arrow as an efficient bridge between R and Spark, conceptually.
X Axis: Time to complete task (left-hand-side is faster)
| |||
(6) Addendum: Diskframe as potential alernative for medium sized projects? | |
| |

References | |
| |
Thanks | |

xavier.depedro (a) seeds4c.org
| |