Big data with Modern R & Spark
"SEMINAR: Análisis de Big data con Tidyverse y Spark: uso en estadística pública"
By Xavier de Pedro Puente, Ph.D.
Senior Technician at the Barcelona City Council.
Outline
- About me
- Barcelona City Council Çase
- Modern R: Tidyverse
- Modern R & Big Data
- Spark (Apache) & Sparklyr (RStudio)
- Sparklyr - next steps
- Alternative approach
- Former hands-on exercise nowadays with sparklyr
(1) About me
Xavier de Pedro Puente, Ph.D. xavier.depedro (a) seeds4c.org
- Academics:
- Current Work:
- Senior technician at Climate Change and Sustainability Office (Barcelona City Council)
- Past (related) Work:
- Senior technician at Development Division, (IMI, Barcelona City Council)
- Senior technician at Municipal Data Office (OMD, Barcelona City Council)
- Bioinformatics technician (UEB, VHIR)
- Systems administrator (UEB, VHIR)
(2) Barcelona City Council Case
- 2018: OMD - Municipal Data Office opened (details):
Management, quality, governance and use of data controlled and/or stored by Barcelona City Council and all of its associated bodies (both public and private).
. - Public Statistics portal
- Recent product: Covid-19 in BCN monitoring with an R Shiny App
Barcelona City Council: Public money - public code
- Barcelona: first city to join the Free Software Foundation, Public Money, Public Code campaign
- One of the case studies of the use of open-source software and open code to democratise cities.
There is a Government policy for open source and agile methodologies
Barcelona City Council: CityOS
City Council's infrastructure based on open-source Big Data technology
City OS: internal data management, known as "Data Lake"
Image from Francesca Bria (Barcelona Digital City Roadmap 2017-2020)
Barcelona City Council: CityOS Technologies
CityOS technologies: GNU/Linux, CentOS, Cloudera, Activiti, Talend, Protégé, R, Zabbix, Nagios, Ganglia
Source: https://github.com/AjuntamentdeBarcelona/CityOS_AjBCN - Image from J. Berdonces a Github
Barcelona City Council: CityOS - Cloudera Manager
Cloudera with Hadoop File System, Hue, HBase, Hive, Impala, Oozie, Spark, Yarn, Kafka, ...
Source: https://github.com/AjuntamentdeBarcelona/CityOS_AjBCN - Image from J. Berdonces a Github
(3) From Base R to "Modern R": Tidyverse
- 2000: First stable beta version (v1.0) released.
- ... "Base R" ...
- 2016: Tidyverse 1.0.0 package released on CRAN
- 2016: "Introduction to Modern R - r4stats.com"
- 2017: "Martin Hadley on R and the Modern R Ecosystem - InfoQ Podcasts"
- 2017: "Modern Data Science with R - Chapman & Hall/CRC"
- 2019: "Modern R with the tidyverse - Econometrics and Free Software" (blog)
- 2019: "Modern R and the Tidyverse - Data Science Workshops"
- 2020: "Modern R: Welcome to the tidyverse" (video tutorial)
- 2020: Statistical Inference via Data Science: ModernDive into R & Tidyverse"
- 2022: Modern R with the Tidyverse

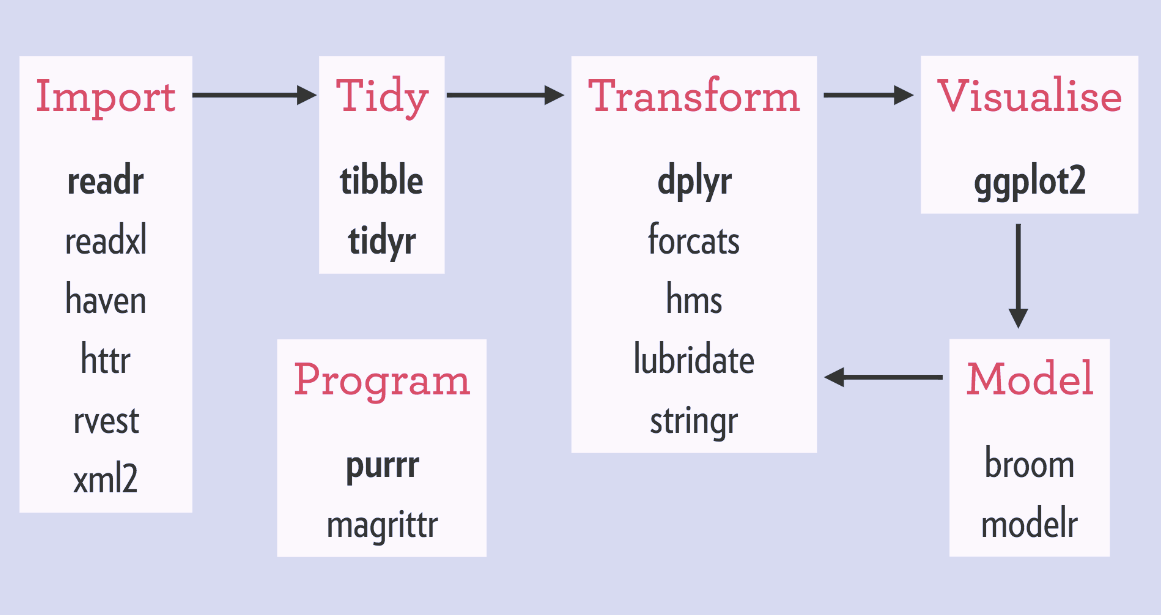
Modern R (Tidyverse)
Workflow, Packages, People/Community
| 
| 
|
Modern R (Tidyverse) principles
- Main structures are ordered data
- Each variable is saved in its own column.
- Each observation is saved in its own row.
- Each "type" of observation stored in a single table
- .Each function represents one step
- Functions are combined with the pipe operator %>%
- or with the earlier pipe from base R: |>
- Each step is a query or command
Derived from here, here & here
(4) Modern R & Big Data
Data > RAM = Problem
From an RStudio seminar by Garrett Grolemund
3 classes of Big Data Problems
From an RStudio seminar by Garrett Grolemund
R interacts with other technologies
From an RStudio seminar by Garrett Grolemund
R General Strategy (i): Class 1 & 2
From an RStudio seminar by Garrett Grolemund
R General Strategy (ii): Class 1 & 2
From an RStudio seminar by Garrett Grolemund
R General Strategy (iii): Class 3
From an RStudio seminar by Garrett Grolemund
Class 3 - dbplyr
R - tidyverse - dplyr + dbplyr
From an RStudio seminar by Garrett Grolemund
R General Strategy (iv): Recap
From an RStudio seminar by Garrett Grolemund
(5) Spark (Apache) & sparklyr (Rstudio)
- Spark, from Apache Foundation: a leading tool that is democratizing our ability to process large datasets.
- R Packages:
- Apache introduced an interface for the R computing language: SparkR R package
- RStudio introduced sparklyr R package: a project merging R and Spark into a powerful tool that is easily accessible to all.
- But why where they introduced?
- And why 2 different packages?
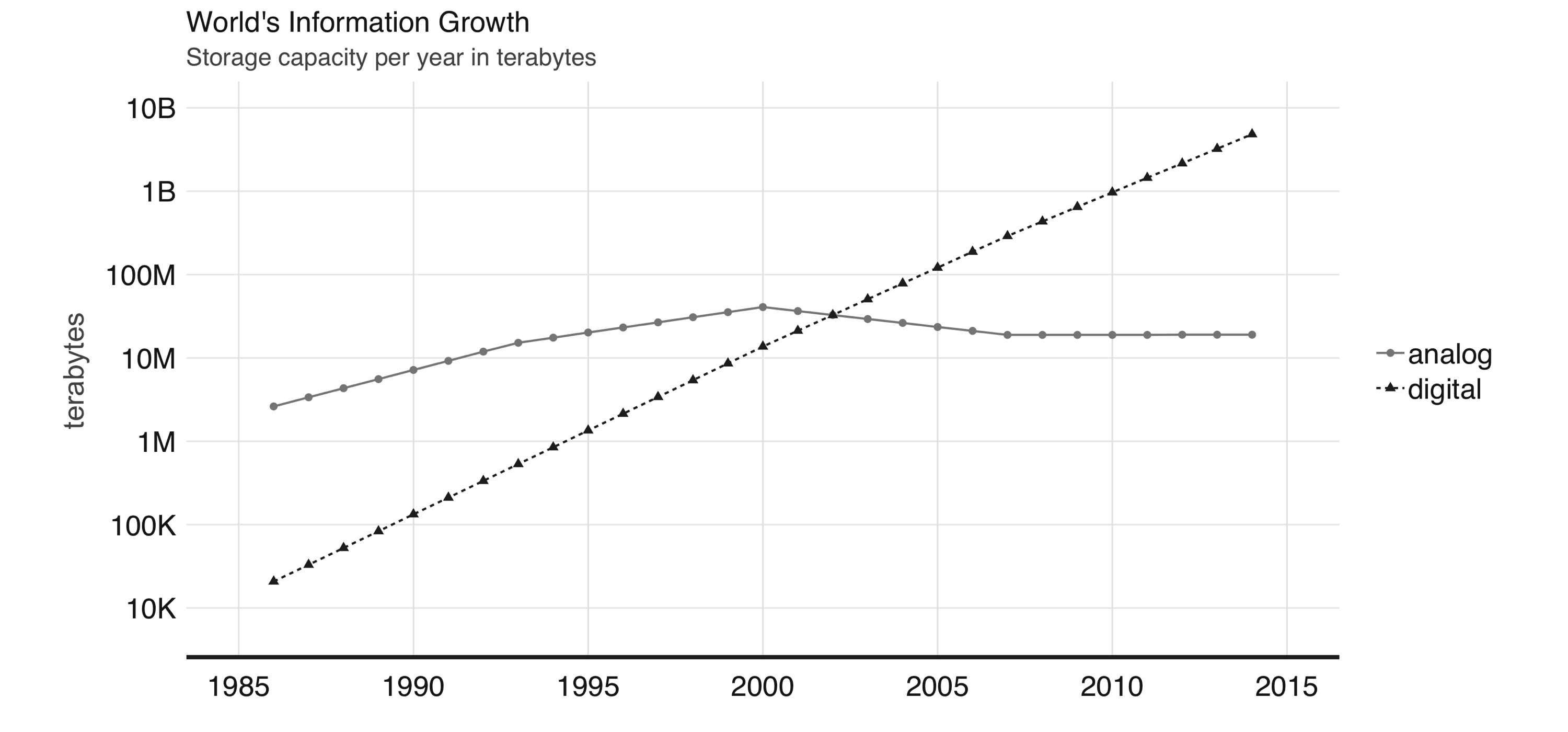
Digital information vs analog information | World Bank - 2003
- World Bank report: digital information surpassed analog information around 2003.
- 10 million terabytes of digital information (~ 10 million storage drives today)
- our footprint of digital information is growing at exponential rates.
Google File System | Google - 2003
- Search engines were unable to store all of the web page information required to support web searches in a single computer.
- They had to split information into several files and store them across many machines
- This approach became known as "Google File System", due to a research paper published in 2003 by Google.
MapReduce | Google - 2004
- 2004: Google published a new paper describing how to perform operations across the Google File System:
- approach called "MapReduce"
- map operation: arbitrary way to transform each file into a new file
- reduce operation: combines two files
- Both operations require custom computer code, but the MapReduce framework takes care of automatically executing them across many computers at once.
- Sufficient to process all the data available on the web, while providing flexibility to extract meaningful information from it.
- approach called "MapReduce"
Hadoop Distributed File System (HDFS) | Yahoo - 2006
- A team at Yahoo implemented the Google File System and MapReduce as a single open source project, released in 2006 as Hadoop
- Google File System implemented as the Hadoop Distributed File System (HDFS).
- The Hadoop project made distributed file-based computing accessible to a wider range of users and organizations, making MapReduce useful beyond web data processing.
![]()
From "The R In Spark" (book) | Image from De Apache Software Foundation, with Apache License 2.0
Hive | Facebook - 2008
- Hadoop provided support to perform MapReduce operations over a distributed file system, but it still required MapReduce operations to be written with code every time a data analysis was run
- Hive project (2008, by Facebook) brought Structured Query Language (SQL) support to Hadoop.
- Data analysis could now be performed at large scale without the need to write code for each MapReduce operation
![]()
From "The R In Spark" (book) | Image from Davod with Apache License 2.0
Spark (closed sourced) | UCBerkely - 2009
- In 2009, Spark began as a research project at UC Berkeley’s AMPLab to improve on MapReduce.
- Spark provided a richer set of verbs beyond MapReduce to facilitate optimizing code running in multiple machines.
- Spark also loaded data in-memory, making operations much faster than Hadoop’s on-disk storage.
Spark: In-memory and on-disk
- Spark: well known for its in-memory performance, but designed to be a general execution engine that works both in-memory and on-disk
- For instance, Spark has set sorting, for which data was not loaded in-memory, but using improvements in network serialization, network shuffling, and efficient use of the CPU’s cache to dramatically enhance performance.
- If you needed to sort large amounts of data, there was no other system in the world faster than Spark.
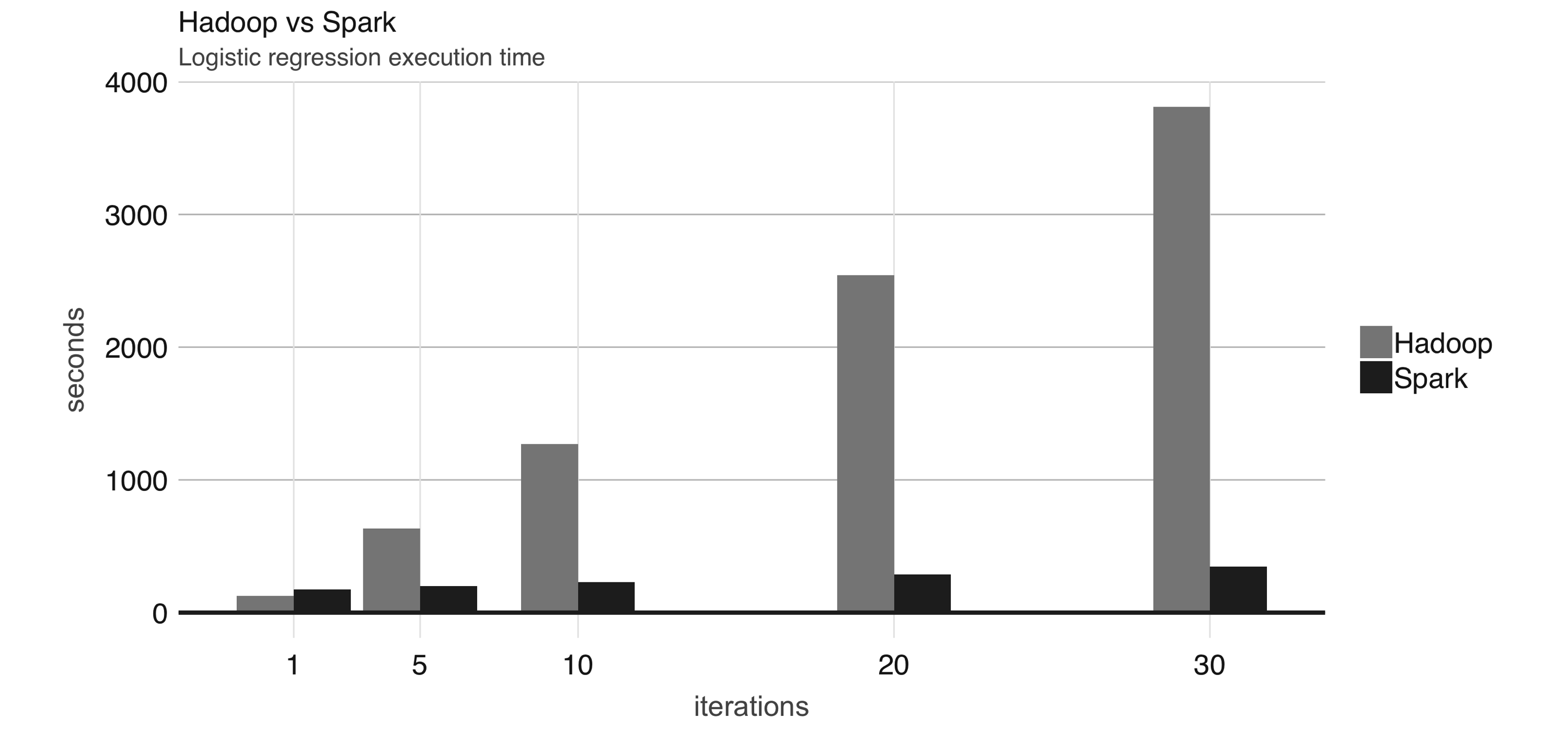
Spark: faster and easier
- Spark is much faster, more efficient, and easier to use than Hadoop.
- Speed Example:
- Without Spark: it takes 72 minutes and 2,100 computers to sort 100 terabytes of data using Hadoop,
- With Spark: only 23 minutes and 206 computers
- Simplicity example: word-counting MapReduce example takes:
- about 50 lines of code in Hadoop, but
- only 2 lines of code in Spark.
| Hadoop Record | Spark Record | |
| Data Size | 102.5 TB | 100 TB |
| Elapsed Time | 72 mins | 23 mins |
| Nodes | 2100 | 206 |
| Cores | 50400 | 6592 |
| Disk | 3150 GB/s | 618 GB/s |
| Network | 10Gbps | 10Gbps |
| Sort rate | 1.42 TB/min | 4.27 TB/min |
| Sort rate / node | 0.67 GB/min | 20.7 GB/min |
Spark (open sourced) - 2010 | Apache Foundation - 2013
- 2010: open sourced. 2013: donated to the Apache Software Foundation
- Apache Spark is a unified analytics engine for large-scale data processing
- Unified: supports many libraries, cluster technologies, and storage systems.
- Analytics: discovery & interpretation of data to communicate information
- Engine: expected to be efficient and generic.
- Large-Scale: as cluster-scale (set of connected computers working together).
| | 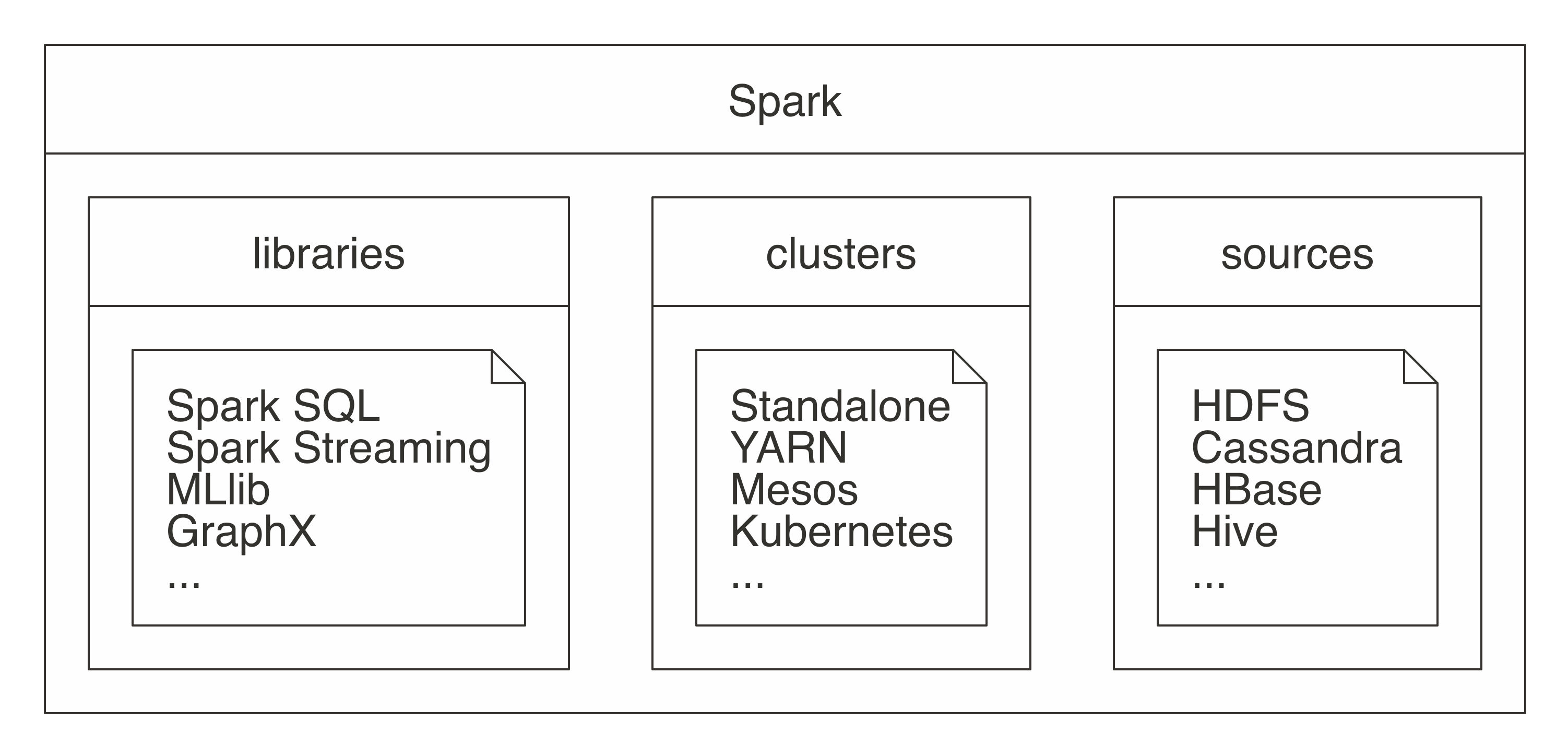
| |
From "The R In Spark" (book) | Image from the Apache Software Foundation, with Apache License 2.0
SparkR (Base R) vs. sparklyr (Modern R)
| Feature | SparkR | sparklyr |
| Data input & output | + + | + + |
| Data manipulation | - | + + + |
| Documentation | + + | + + |
| Ease of setup | + + | + + |
| Function naming | - - | + + + |
| Installation | + | + + |
| Machine learning | + | + + |
| Range of functions | + + + | + + |
| Running arbitrary code | + | + + |
| Tidyverse compatability | - - - | + + + |
From https://www.eddjberry.com/post/2017-12-05-sparkr-vs-sparklyr/
Sparklyr | RStudio
- Sparklyr, from Rstudio: https://spark.rstudio.com/
- R interface for Apache Spark, agnostic to Spark versions,
- 2016: 1st version released (v0.4)
- Easy to install, serving the R community,
- Embracing other packages & practices from the R community (tidyverse, ...)
- Designed for: New Users, Data Scientists, and Expert Users
Image from here
Summary: Big Data with Modern R & Spark
Big Data with Modern R & Spark in context
Image from here
Speeding up Spark via R with Apache Arrow
Apache Arrow is a cross-language development platform for in-memory data, you can read more about this in the Arrow and beyond blog post. In sparklyr 1.0, we are embracing Arrow as an efficient bridge between R and Spark, conceptually.
![]()
X Axis: Time to complete task (left-hand-side is faster)
Y Axis: Top section: WITHOUT Apache Arrow), Bottom section: WITH apache Arrow.
| Copying: | Collecting: | Transforming |
From: https://arrow.apache.org/blog/2019/01/25/r-spark-improvements/
(6) Sparklyr - next steps
From: https://github.com/harryprince/awesome-sparklyr
(7) Addendum: Diskframe as potential alernative for medium sized projects?
-
disk.framepackage, answer to: how do I manipulate structured tabular data that doesn’t fit into Random Access Memory (RAM)?. - It makes use of two simple ideas

- split up a larger-than-RAM dataset into chunks and store each chunk in a separate file inside a folder and
- provide a convenient API to manipulate these chunks
- It performs a similar role to distributed systems such as Apache Spark, Python’s Dask, and Julia’s JuliaDB.jl for medium data which are datasets that are too large for RAM but not quite large enough to qualify as big data.
More information: here and here
(8) Former hands-on exercise nowadays with sparklyr
Remember the hands on exercise we did on the session about "Reproducible Work in Data Science" in this postgraduate course?
We will revisit the work we did in that session, and we will evolve the Rmd you did in order to adapt it to use sparklyr to achieve the goal we had in that hands-on exercise.
We can't make use of the posit.cloud free plan since the Spark infraestructure we need does require more than just 1 Gb of RAM (the RAM provided for free in posit.cloud free plan).
So that in this seminar, we will see the job performed in datascience.seeds4c.org, which is a lxc (linux container) based on Ubuntu 20.04 LTS with 4Gb of RAM and 4 cpu.
http://datascience.seeds4c.org:8787/
We will run this code chunk by chunk, to assess the RAM and time consumed to perform the same task with and without sparklyr in the same container.
https://gitlab.com/xavidp/datascience2023/-/blob/master/DATA_SMC_with_sparklyr.Rmd
Task: just loading the whole dataset (600 Mb csv file on disk), for instance, and saving it partitioned by meterological station to csv files on disk:
- From 117 Mb (and 63 secs) in the R Session using sparklyr to 1560 Mb (and 165 secs) if using just R (not involving Spark).
References
- TheRinSpark Book: https://therinspark.com/
- Cheatsheets at https://www.rstudio.com/resources/cheatsheets/
- And some in Spanish Cheatsheets URL > Spanish Translations – Traducciones en español
- Posit (Rstudio) Cloud (with free plan): https://posit.cloud/plans
- Webinars & scripts for hands-on practising:
- Compilation of links related to sparklyr: https://github.com/harryprince/awesome-sparklyr
- Playground for R & Spark (14d for free): https://community.cloud.databricks.com/ Pricing
- Tidyverse Skills for Data Science. Carrie Wright, Shannon E. Ellis, Stephanie C. Hicks and Roger D. Peng. 2021-09-02
Thanks

Unless elsewhere noted, contents of this web site are released under a Creative Commons license.